Bayesian Statistical Learning Model
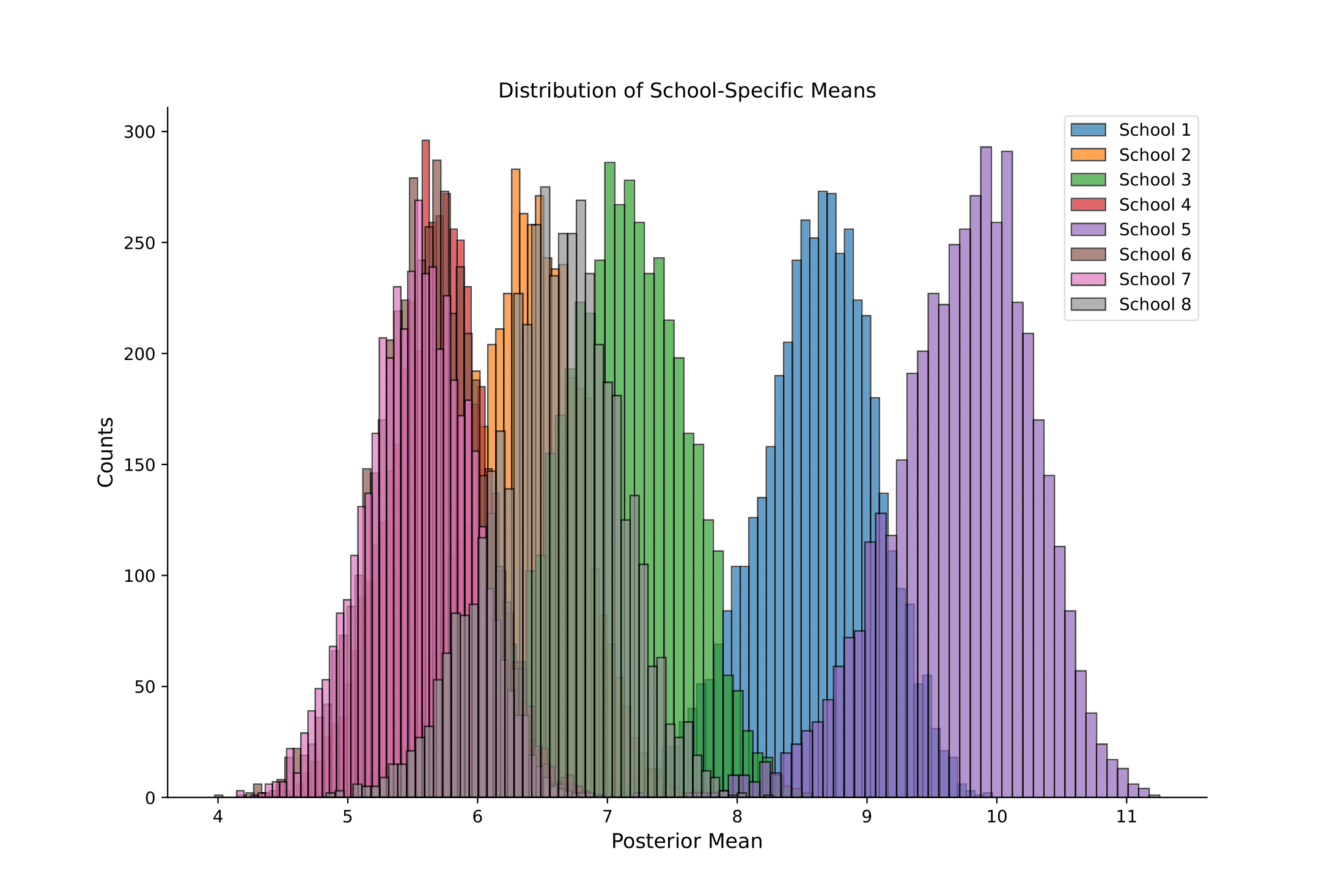
During my Senior year of college I took a class on Bayesian statistics. While incredibly interesting and informative, it was a lot of work. Nonetheless, I learned a lot! Much of the work was focused on computational statistics, including generalized linear models, hierarchical modeling, and gaussian processes, as well as sampling algorithms, such as Metropolis-Hastings and Gibbs sampling. The final project for the course involved creating a Bayesian statistical model for analyzing real-world data. My partner and I focused on building a model for predicting life expectancies based on a paper from Raftery, et al. The full and associated code can be found above (the repository name was recommended by GitHub and it was too good to pass up).
Whether it be the algorithm we created or simply the dimension of the data, the sampling algorithm we tried to run took ages. Hence, a significant amount of random sampling was done using supercomputing clusters provided by Hopkins. That is, I’d suggest not running this code on your desktop unless you have three hours to kill and a very powerful fan.
Reference
Adrian E. Raftery, Jennifer L. Chunn, Patrick Gerland & Hana Ševčíková (2013). Bayesian probabilistic projections of life expectancy for all countries. Demography. 50:3, 777-801. DOI: 10.1007/s13524-012-0193-x.